数值分析方法
数值方法可以用近似方法来理解
对于一些得不到解析解否则解析解计算难度太大的问题,如何用
较少
的计算得到
相对较好
(满足精度要求)的数值解、近似解。

数值分析最基本的立足点是容许误差
例子:


近似计算基本方法:
- 离散化(e.g. 数值积分)
- 递推法(将一个复杂的计算过程转化为简单过程的多次重复 e.g. 上面的第二个例子)
- 近似替代法(将无限过程的数学问题用计算机的有限次计算近似替代 e.g. 上面的第一个例子Taylor公式不可能计算无限次,必须要近似替代)
不是解析解买不起,而是数值解更有性价比
接下来会介绍最常用的数学模型的最基本的数值计算方法

有关误差的一些基本概念
误差的来源与分类


前两种误差和数值方法本身无关,数值方法应重点关注截断误差和舍入误差
算法稳定性的概念: 初始的小扰动迅速积累,误差呈递增走势。——不稳定的算法!
误差逐步递减, 这样的算法称为稳定的算法。
误差和误差限
绝对误差:
\(\epsilon(x) = x^* – x ,其中x^*为近似值\)
可正可负可为0
准确值
\(x\)
一般无法确切知道,所以我们一般估计一个绝对误差的上界,
\(|\epsilon(x)| \le \eta\)
?绝对误差限
\(\eta\)
显然是正值
相对误差
\(\epsilon_r(x) = \frac{x^* – x}{x}\)
可正可负可为0

同样的前提下

相对误差、相对误差限是无量纲的量
相对误差限比绝对误差限能更好地刻画近值数的近似程度
有效数字


准确到小数点后第 j 位 ? 保留k + j 位有效数字 ? 绝对误差限不超过
\(0.5*10
^{−j}\)
\(x^*\)
可表示为
\(\pm0.x_1x_2….x_n * 10^m, 其中x_1 \ne 0\)
,
若
\(x^*\)
有效数字的位数为 n,则有
\(x^*\)
的相对误差限
\(\eta_r\)
为
\(\frac{1}{2x_1}*10^{1-n}\)
若
\(x^*\)
的相对误差限
\(\eta_r\)
为
\(\frac{1}{2(x_1 + 1)}*10^{1-n}\)
,则
\(x^*\)
有效数字的位数为 n
证明:


算术运算的误差与误差限
加减法:


乘法:

除法:

当除数绝对值较小时,商的绝对误差的绝对值将非常大
幂、对数:


近似计算应遵循的原则

为什么?



若干值得注意的问题
-
防止两个相近的数相减 ? 会使有效数字的位数严重损失

-
避免除数的绝对值 << 被除数的绝对值 ? 除数稍有一点误差,则计算结果会出现较大变化

-
防止大数“吃掉”小数
计算?计算浮点数时对阶后可能出现较小数的尾码变成全0 -
简化计算步骤,减少运算次数

插值方法

已知一组离散数据,人们希望建立一个简单的而便于计算的函数 g(x)使其近似的代替 f(x)
插值多项式的存在性与唯一性


该行列式可以用范德蒙行列式的公式计算,因为
\(x_i\)
是互异的节点,所以行列式的值不为0
可以用求解线性方程组的方法可以确定插值多项式 pn(x),
但是当 n 较大时,这种方法的计算量非常大。
拉格朗日(Lagrange)插值
n + 1个插值节点 ? n + 1个限制条件 ? n + 1个插值基函数 ? n次拉格朗日差值多项式
插值基函数

插值基函数很好写,该函数是
\(n\)
次多项式,且已知它的
\(n\)
个零点,常量系数只需要满足当代入
\(x_i\)
时基函数值为1即可
拉格朗日插值多项式是插值基函数的线性组合
这样写出的n次拉格朗日插值多项式一定满足所有限制条件,且插值多项式存在且唯一,故拉格朗日插值多项式就是我们想要的插值多项式
误差分析:

设在
\(x\)
处的误差
\(f(x) – L_n(x)\)
可以表示为
\(c\omega(x)\ 也即\ c\prod_{i =0}^{n}(x-x_i), 这里c并不是一个常量,它是x的函数\)
接下来构造一个具有n + 2个零点的函数,且该函数包含误差的表达式
\(f(x) – L_n(x)\)
在插值区间
\([a, b]\)
中找到一个不是插值节点的
\(x\)
,在该点的误差为
\(c_x\omega(x)\)
构造的函数为
\(F(t) = f(t) – L(t) – c_x\omega(t)\)
这样的函数在所有的插值节点和x处函数值为0,一共n + 2个零点

对表达式
\(F(t) = f(t) – L(t) – c_x\omega(t)\)
左右两边对t求n+1阶导数 (t与x没有任何函数关系)

代入点
\(\xi\)

注意这里的
\(\xi\)
与我们选取的x有关,存在某种未知的函数关系



牛顿(Newton)插值
Lagrange 插值虽然简单,但每增加一个节点,原有的插值基函数
\(l_i(x)\)
必须重新计算,从而不具有承袭性 ? 增加一个节点原本的所有插值基函数都多了一个新的零点,且系数k也随之改变
因此引入Newton插值

多一个节点,只要基于前一个
\(\phi(x)\)
构造一个新的
\(\phi(x)\)
加进多项式中即可,之前的系数也不需要改变(新加入的
\(\phi\)
函数在前面的插值节点处的函数值为0)
特征: 在
\(x_i\)
处的函数值仅由0~i个
\(c_i * \phi(x)\)
决定
引入差商的概念给出Newton插值的插值公式

计算差商时画出差商表方便计算

差商的一些性质:
差商
\(f[x_0,x_1,…x_k]\)
是
\(f(x)\)
在
\(x_0,x_1,…x_n\)
处函数值的一个组合,组合的系数是一个连乘形式的倒数

该性质的证明可以用数学归纳法,首先0阶差商就是函数值显然成立,之后由k = n-1 时成立推出 k = n时成立
由差商是函数值的线性组合可以看出,差商的值与各点的排列顺序无关
差商
\(f[x,x_0,x_1,…x_k]\)
同样可以写成组合形式,只不过其中一个节点要替换成x,则它应该是x的函数
根据定义

可以确定,如果
\(f[x,x_0,x_1,…x_k]\)
是x的n次多项式,那么
\(f[x,x_0,x_1,…x_k,x_{k+1}]\)
是x的n-1次多项式
这个可以从组合形式中定性地看出,对于x来说,f(x)的次数不变,分母的
\((x-x_0)(x-x_1)…(x-x_k)\)
多了一项,那么次数应该减少一次
也可以从定义式中推断,因为
\(f[x,x_0,x_1,…x_k,x_{k+1}]\)
可以写成
\(\frac{f[x_0,x_1,…x_k,x_{k+1}]-f[x,x_0,x_1,…x_k]}{x_{k+1} – x}\)
,且已知
\(f[x,x_0,x_1,…x_k]\)
是n次多项式,
\(f[x_0,x_1,…x_k,x_{k+1}]\)
是常数,且分子在
\(x=x_{k+1}\)
时为0,故n次多项式含有
\((x-x_k+1)\)
因子,可以和分母约掉,故整体是n-1次多项式
进一步地

Newton插值用差商表示可以写成

该形式在
\(x_0\)
点显然成立,在其他任意点由差商的定义
\(f[x,x_0] = \frac{f(x) – f(x_0)}{x – x_0}\)
也显然成立
同时
\(f[x,x_0,x_1] = \frac{f[x_0,x_1] – f[x,x_0]}{x_1 – x}\)
推出
\(f[x,x_0] = f[x,x_0,x_1]*(x – x_1) + f[x_0,x_1]\)
所以
\(f(x) = f(x_0) + f[x_0,x_1](x-x_0)+f[x,x_0,x_1](x-x_0)(x-x_1)\)
推广到n+1个点时,就是

可以发现前面的
\(c_n\)
就是Newton插值的形式,后面的
\(R_n\)
是牛顿插值的余项
由插值多项式的唯一性可知,同为n次多项式的Newton插值和Lagrange,同为n次多项式的Newton插值和Lagrange插值是完全相等的,故余项也是相等的

赫密特(Hermite)插值
就是限制条件变多的Lagrange插值
现在要求在插值节点处插值多项式的导数值要和f(x)一致
同样的思路写出插值基函数
n + 1个插值节点 ? 2n + 2个限制条件 ? 2n + 2个插值基函数

插值基函数同样很好写,在
\(\alpha_i\)
在
\(x_i\)
以外的点值为0,导数值也为0,故包含
\((x – x_j)^2\)
因子,因为是2n+1次多项式,待定系数法
\((ax+b)\)
,使得在
\(x_i\)
处插值基函数的值为1,导数值为0
\(\beta_i\)
同样含有2n次的因子,且
\(\beta_i\)
在
\(x_i\)
处函数值为0,故还含有
\((x-x_i)\)
因子,故待定系数求一常数即可,该常数使
\(\beta_i\)
在
\(x_i\)
处导数值为1
误差分析:
和Lagrange插值多项式的证明类似,得到插值余项为

注意
\(R_{2n+1}(x)\)
在插值节点处的值为0,且
\({R_{2n+1}}'(x)\)
在插值节点处也为0 ?
\(\omega(x)\)
的作用
分段插值
由于Rouge现象的出现,我们将大区间分段,每段用由较少插值节点得到的低阶插值多项式进行拟合

缺点:在分段处不够光滑
误差分析:
在每段用和Lagrange插值同样的误差分析进行分析

其中
\(h_i\)
是第i个分段的长度
其他分段插值的误差分析与之类似,都是找到所有段中Lagrange误差余项最大的那个作为整体的误差上界
曲线拟合
曲线拟合是给定函数类H,按照某种准则,找到一条曲线,既能反映给定数据的总体分布形式,又不致于出现局部较大的波动
和插值不同,插值只要在插值节点处满足插值条件即可,而曲线拟合是为了反映给定数据的分布
插值在局部的插值节点是精确的,而曲线拟合在给定的点处允许误差,期望在整体分布上是准确的
曲线拟合的最小二乘法
最小二乘法的出发点:

找到的g(x)在函数类H中计算得到的残差平方和一定是最小的
做法:待定系数法,根据最小二乘条件解方程
直线拟合


多项式拟合






数值积分
虽然数学题中的积分往往可以找到原函数用牛顿-莱布尼兹公式求出解析解,但实践中常常找不到原函数或者被积函数都是以离散形式给出的(例如插值问题中,就不知道f(x)是什么,但我们可能需要求其积分)
故根据积分的定义,采用计算机累加的方法进行计算

机械求积公式和代数精度

机械求积公式尝试给出
\(f(\xi)\)
的近似值



误差分析:

引入代数精度的概念

对m次多项式成立,只需要求积公式分别对
\(f(x)为x^0,x^1,..x^m\)
成立即可 ? 积分的线性性质,即
\(∫(f(x)+h(x))dx=∫f(x)dx+∫h(x)dx\)

定理的意义:给定若干节点,机械求积公式的积分精度是有保证的

同时也说明f(x)用n次Lagrange插值来近似后再进行积分计算,代数精度是n
机械求积公式中的
\(A_i\)
可以用
\(\int_a^bl_i(x)\)
计算得到
求积公式的构造方法
从前面的分析可知,存在特定的系数使k+1个节点组合得到的求积公式的代数精度至少为k
可以根据代数精度的判断条件,解方程求得

也可以用n次Lagrange插值近似被积函数,同样的代数精度为n

当被积函数本身就是不大于n次的代数多项式,那么n次Lagrange插值多项式实际上等价于被积函数(Lagrange余项为0),那么插值型求积公式就是精确的
可以证明

如果代数精度至少为n次,那么该公式对于
\(l_j(x)\)
是精确的,因为
\(l_j(x)\)
是n次多项式,那么
\(\int_{a}^{b} l_j(x) \,dx = \sum_{i=1}^{n}A_il_j(x_i)\)
因为
\(l_j(x_i)\)
只有在
\(i=j\)
时为1,其他点都为0,则有
\(\int_{a}^{b} l_j(x) \,dx = A_j\)
,对于所有的n+1个插值基函数都有这一结论,根据积分的线性性质,可以知道求积公式是插值型的
另一方面,如果求积公式是插值型的,说明我们用n次Lagrange插值对被积函数进行了近似。那么我们可以将被积函数
\(f(x)\)
分为两部分,一部分是不大于n次的多项式,另一部分是高于n次的多项式,因为不大于n次的部分在近似后是可以精确求积的,故代数精度至少为n。
Newton-Cotes 求积公式
上面的机械求积公式对
\(x_i\)
的选取没做限制,因为
\(A_i = \int_a^bl_i(x)\)
,则当节点改变或者求积区间改变时,求积公式中的系数
\(A_i\)
需要重新计算
但如果我们将求积区间独立出来,且规定
\(x_i\)
是区间的n等分点,将
\(A_i\)
用Cotes系数
\(C_i\)
代替,可以发现系数既与求积区间
\([a,b]\)
无关,也与节点
\(x_i\)
的值无关,仅与总的节点个数n有关
-
求积区间独立出来

-
节点是区间的n等分点

最后的积分形式只有一个n是可变的量,所以Cotes系数对于给定的节点满足条件的积分都适用
记住常见的Cotes系数

误差分析:

注意这里的
\(f^{(n+1)}(ξ)\)
不能视为常数提到积分式之外,回忆Lagrange插值的误差分析,
\(ξ\)
是
\(x\)
的函数,故也是
\(t\)
的函数
这也是求积公式误差分析的难点所在

因为
\((t-0)(t-1)…(t-n)\)
中n为偶数,故该函数关于
\((\frac{n}{2},0)\)
中心对称,该函数积分值为0。
稳定性分析

截断误差在上一节给出了通式
舍入误差是由机器字长有限导致的
接下来分析Newton-Cotes公式的稳定性

这里第一行的
\(≈\)
是截断误差(代数精度至少为n,则高于n次的项可能积分值有误)

常见Newton-Cotes公式
梯形公式



这里由第一行变到第二行用到了积分第二中值定理来将
\(f”(ξ)\)
提出来,
\(t^2-t\)
在
\([0,1]\)
区间上是小于0不变号的
积分第二中值定理如下

辛普森公式
(三个节点,二阶Lagrange,代数精度为三)


因为Simpson公式的代数精度为3,分析其误差则需要将
\(f(x)\)
表示为某个三次插值多项式与其余项之和,然后再求余项的积分
如果使用Lagrange插值多项式,辛普森公式没法像梯形公式那样,在分析误差时直接使用积分第二中值定理来将
\(f”'(ξ)\)
提出来,因为另外一部分
\((t-0)(t-1)(t-2)(t-3)\)
不满足积分区间上不变号的条件
所以改用Hermite插值多项式来满足不变号的条件



柯特斯公式
(五个节点,四阶Lagrange,代数精度为五)


三种求积公式及其余项

复化求积法
在一定范围内,求积公式的代数精度随插值节点的增加而提高,但高次插值会出现Rouge现象,导致近似效果变差,则对近似函数求积得到的结果也变差。
且n 较大时,Newton-Cotes 系数不容易求解,且出现负数项,高阶Newton-Cotes 公式数值不稳定。
又从余项的讨论看到,积分区间越小,求积公式的截断误差也越小。
因此,我们经常把积分区间分成若干小区间,在每个小区间上采用次数不高的插值公式,构造出相应的求积公式,然后再把它们加起来得到整个区间上的求积公式,这就是复化求积公式的基本思想。
复化T公式


误差分析:
复化求积公式总的误差等于所有小区间的误差之和
注意这里的h是复化梯形公式的步长
\(\frac{b-a}{n}\)
,而不是
\(b-a\)

最后一行使用了介值定理
复化S公式
区间
\([a,b]\)
实际上划分为m块,每块用Simpson公式,Simpson公式的步长是
\(\frac{1}{2}\)
区间长度,故总共
\(n\)
等分,
\(n = 2m\)
,步长为
\(\frac{b-a}{n}\)
Simpson公式的系数是
\(\frac{1}{6} ,\, \frac{4}{6}, \, \frac{1}{6}\)


误差分析:
注意共有m个小区间,步长h是每一小步的长度

复化C公式
Cotes公式的系数是
\(\frac{7}{90} ,\, \frac{32}{90} ,\, \frac{12}{90} ,\, \frac{32}{90} ,\, \frac{7}{90}\)

误差分析:
注意共有m个小区间,步长h是每一小步的长度

Romberg 求积公式
从上述误差分析可以看到,复化积分的截断误差随着分割因子 n 的增大而减小
如何根据精度要求选取合适的步长呢?
二分法:
以梯形公式为例


该过程收敛速度较慢
对复化公式进行分析

注意从第一行公式到第二行公式有一个近似替换,将大区间n等分后小区间上离散的函数值乘步长的累加近似为大区间上的积分

将
\(\overline{T}\)
展开合并同类项可以发现

定性地比较一下复化T,复化S和复化C公式的误差



可以发现
复化T每二分一次,误差近似变为原来的
\(\frac{1}{4}\)
。
复化S每二分一次,误差近似变为原来的
\(\frac{1}{16}\)
。
复化C每二分一次,误差近似变为原来的
\(\frac{1}{64}\)
。
经过上面的分析,得到Richardson(理查德森)外推表


在复化T公式二分的同时,利用Richardson 外推进行加速
数值微分
给定某未知函数上若干离散的点的值,期望得到该函数的导函数(近似导函数)
差商型数值微分




误差为


插值型数值微分
利用插值多项式近似函数,再求导

误差分析:

当x取插值节点时,即求插值节点处的导数值, 因为
\(\omega_{n+1}(x) = 0\)
, 误差中的后一项为0
常见的插值型数值微分(一般写出Lagrange插值再求导即可):
两点公式

带有余项的两点公式

三点公式


常微分方程数值解法
该类问题是给定一个常微分方程,求满足该方程的函数
n阶常微分方程形如

n阶常微分方程一般会给定n个初值或者n对边值
引言

存在唯一解的
充分
条件:

如何计算
\(y(x)\)

约定
\(y(x_n)\)
为待求函数 y(x) 在
\(x_n\)
处的精确函数值,
\(y_n\)
为待求函数 y(x) 在
\(x_n\)
处的近似函数值
补充的数学知识:



多元函数f(x,u,t)对x求导,其中u是x的函数,t与x无关 ? 则
\(f'(x,u,t) = f_x(x,u,t) + f_u(x,u,t)u'(x)\)
, 同样的求n阶导可以视为对n-1阶导函数求导
则上式中
\(\frac{\partial f(x_n,y_n)}{\partial x}\)
的计算结果就是
\(f_x(x_n,y_n)+f_y(x_n,y_n)y'(x_n) = f_x(x_n,y_n)+f_y(x_n,y_n)f(x_n,y_n)\)
欧拉方法
欧拉方法是常微分方程的一种数值解法
其基本思路是不求
\(y(x)\)
的解析解,而是对求解区域
\([a,b]\)
做等距剖分,求
\(y(x)\)
在剖分节点
\(x_n\)
上的近似值
\(y_n\)
因为我们已经知道了导函数的表达形式
这一点可以由初值加上在剖分区间上的数值积分做到
(当然也可以将导数转化为剖分节点的差商)

h为剖分区间的长度
途径一:化导数为差商的方法




单步欧拉法仅需要当前步的信息来计算下一步,二步欧拉法需要当前步和前一步的信息来计算下一步
途径二:初值+数值积分




梯形公式欧拉法

常微分方程数值解是一组离散的函数值数据,它的精确表达式很难求解得到,但可以进行插值计算后用插值函数逼近 y(x)
局部截断误差分析

注意这里和代数精度的区别
在上一步
\(y_n\)
精确的前提下,截断误差就是剖分区间上数值积分的误差。显然剖分区间越大,那么积分带来的误差也越大,故误差可以用h的次方来衡量。
而代数精度是对于次数不大于n的代数多项式,求积公式准确成立。
局部截断误差可以用泰勒展开进行分析
因为上一步准确,所以
\(y(x_n) = y_n\)
,且有常微分方程可知
\(y'(x_n) = f(x_n,y(x_n))\)
泰勒展开
\(y(x_{n + 1}) = y(x_n + h) = y(x_n) + y'(x_n)h + \frac{y”(ξ)}{2}h^2\)
-
显式一步欧拉
\(y_{n+1} = y_n + hf(x_n,y_n) = y(x_n) + hf(x_n, y(x_n)) = y(x_n) + hy'(x_n)\)
故误差为
\(T_{n+1} = \frac{y”(ξ)}{2}h^2 = O(h^2)\)
一阶精度 -
隐式一步欧拉
$y_{n+1} = y_n + hf(x_{n+1},y_{n+1}) $
这里做一个不甚精确的假设:我们计算的
\(y_{n+1}\)
可以近似地当作
\(y(x_{n+1})\)
代入到
\(f\)
中
则
\(y_{n+1} = y(x_n) + hf(x_{n+1}, y(x_{n+1})) = y(x_n) + hy'(x_{n+1})\)
我们可以对
\(y'(x_{n+1})\)
进行泰勒展开
得到
\(y_{n+1} = y(x_n) + h(y'(x_{n}) + O(h))\)
则
\(y_{n+1} = y(x_n) + hy'(x_{n}) + O(h^2)\)
故误差
\(T_{n+1} =y(x_{n+1}) – y_{n+1} = \frac{y”(ξ)}{2}h^2 – O(h^2) = O(h^2) – O(h^2) = O(h^2)\)
一阶精度 -
显式二步欧拉法
做法是类似地,将
\(y(x_{n-1})\)
在
\(x_n\)
处进行泰勒展开,之后作差

二阶精度 -
梯形公式欧拉法(隐式单步)
梯形公式就是显式和隐式一步欧拉法的算数平均,证明不做赘述

二阶精度

改进的欧拉方法
从上述例子可以看到,梯形法由于具有二阶精度,其局部截断误差比显式欧拉法和隐式欧拉法小,但梯形
法是一种隐式算法,需要迭代求解,计算量大。
显式欧拉法是一个显式算法,虽然计算量较小,但是精度不高。
改进的欧拉方法则先用显式欧拉法计算
\(y_{n+1}\)
,代入到梯形法的右式中求更精确的
\(y_{n+1}\)
改进的欧拉法也被称为预报-校正法,第一个
\(y_{n+1}\)
是预报值,第二个
\(y_{n+1}\)
是校正值
改进的欧拉法具有二阶精度


当然也可以多次进行预报-校正过程

几何意义
根据
\((x_n,y_n)\)
的信息估计一个值,根据估计值的信息重新估计一个值,取两者的平均

龙格-库塔方法
根据上面的分析,改进的欧拉法在剖分区间中预报了一个值,精度较显式欧拉法有所提高
龙格-库塔方法的思想是在剖分区间内多预报几个点
\(k_i\)
的值,并用其加权平均值作为
\(k^*\)
的近似值

p阶R-K公式如何构造可以通过泰勒展开进行求解
以二阶R-K公式构造过程为例

展开过程略


四个未知量,三个方程,有无穷多解,且满足方程组的任意一组系数构成的R-K公式都是2阶精度的
其中包括了改进的欧拉法和变形的欧拉法

三阶四阶的R-K公式也可以用一样的方法求解
三阶R-K公式,8个未知量,6个方程,无穷多组解
最常用的是库塔公式

四阶最常用的是标准四阶龙格库塔公式和吉尔公式


实际应用中一般选四阶及以下的龙格-库塔
四阶以上龙格-库塔公式的计算量太大,并且精度不一定提高,有时反而会降低
变步长的龙格-库塔
我们知道步长小精度高,步长大计算量小,那么如何选择合适的步长呢?
变步长的龙格-库塔就是为了解决这个问题


这一点很好理解,假设
\(y_{n+1}^{(h/2)}\)
的误差是
\(a\)
,因为
\(y_{n+1}^{(h)}\)
的误差差不多是
\(y_{n+1}^{(h/2)}\)
误差的
\(16\)
倍,且这两个点不一定在精确解在数轴上的点的同一侧,故两点的距离最小是
\(15a\)
,即
\(|y_{n+1}^{(h)} – y_{n+1}^{(h/2)}|>15a\)
,又
\(|y_{n+1}^{(h)} – y_{n+1}^{(h/2)}|<15\epsilon\)
,故
\(a<\epsilon\)
,也就满足了精度要求
有了判断所选步长是否满足精度要求的方法,我们就可以根据解的性态来调整步长的大小:在变化平缓的部分,数值求解使用较大步长;而在变化剧烈的部分,则使用较小步长
收敛性与稳定性
收敛性和稳定性的分析较难
我们接下来仅对较简单模型的收敛性和稳定性进行分析
收敛性
收敛性的定义

虽然我们之前的误差分析中,误差最小是
\(O(h^5)\)
,当
\(\lim\limits_{h \to 0}\)
时,误差显然为0,但我们之前分析的误差都是局部误差,建立在上一步结果精确的前提下。虽然我们现在每一步的误差都近似为0,但同样地
\(\lim\limits_{h \to 0}\)
也意味着
\(\lim\limits_{n \to \infty}\)
,现在有无穷多步。
但
\(n\)
与
\(h\)
应满足
\(n*h\)
是一个定值
\((x_n-x_0)\)
接下来我们仅对单步显式方法进行分析
判断收敛的方法是收敛性定理

证明

首先可以将误差拆分成局部误差和
\(|\overline y_{n+1} – y_{n+1}|\)
两部分误差的和
局部误差是
\(O(h^{p+1})\)
,后一部分误差利用Lipschitz条件,可以变成常数与前一步误差的积
最终得到一个递归式


利用
\(e^x>(1+x)\)
进行放缩,使
\(nh\)
凑到一起,变成常数
同时
\(|\epsilon_0| = 0\)
,使得最终的误差为0
稳定性
稳定性的定义我们已经介绍过了,稳定性用来判断算法的舍入误差(微小扰动)是否会积累(恶性增长)的概念。

这里只研究
\(y’=\lambda y \, (\lambda < 0)\)
,也即
\(y = e^{\lambda x} \, (\lambda < 0)\)
的情况
显式欧拉法:

注意这里的假设,可以看出对该模型稳定性的分析只是一个定性的分析

隐式欧拉法:

方程求根
rt,本章研究方程求实根的数值方法(一般是次数大于4的多项式方程或超越方程,低次的多项式方程有求根公式)
三个步骤:

二分法
一种很经典的解法,原理是零点存在定理,前提是给定一个有根区间


在迭代的过程中维护一个性质,即左端点和右端点满足
\(f(left)*f(right)<0\)
,每次迭代取区间的中点进行判断,将有根区间二分

结果取有根区间的中点即可

迭代法

具体步骤:

可以证明收敛的迭代序列一定收敛于方程的解

注意中间的变换要求
\(φ(x)\)
l连续
迭代法的几何意义:
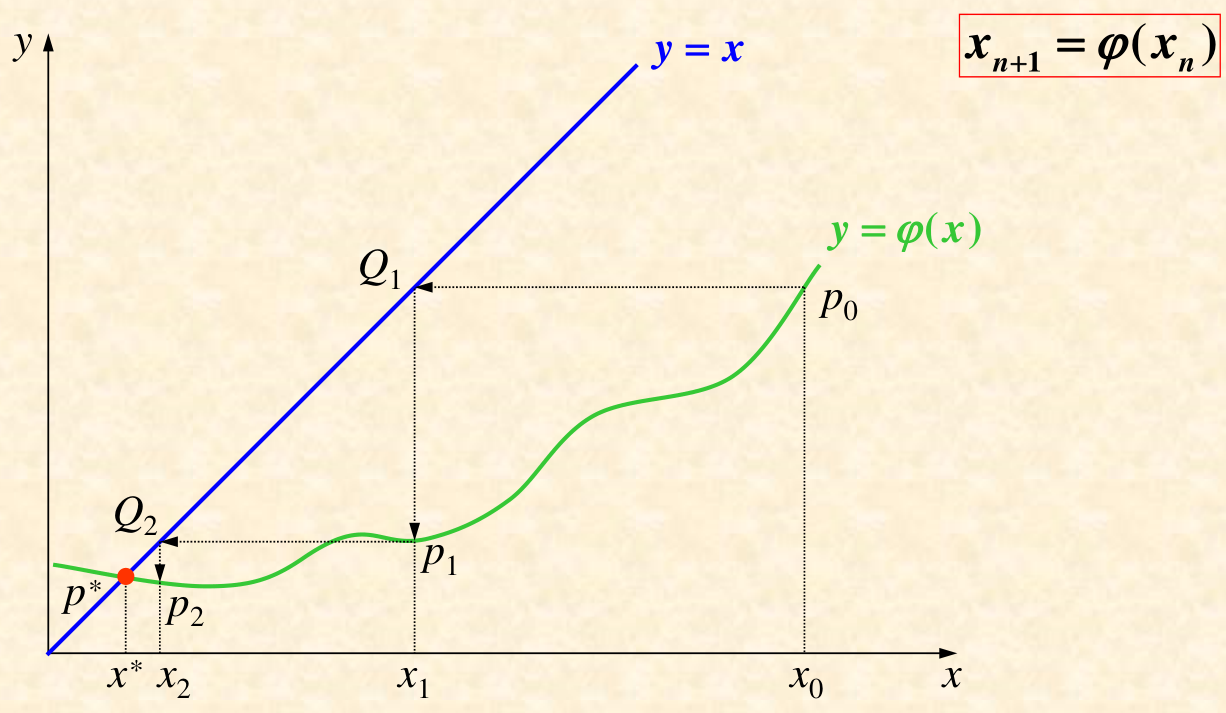
注意
\(y = φ(x)\)
与
\(y = x\)
的交点就是根
该方法还存在两个问题:
-
不是所有迭代序列都是收敛的,如何找到收敛的迭代序列(即如何选择初值
\(x_0\)
和迭代方程
\(x=φ(x)\)
) - 收敛序列的收敛是用极限来判断的,但我们不可能无限算下去(即判断什么是否停止计算,也即给出迭代到第k步的误差分析)
这两个问题在下一节解决
迭代法的收敛性与误差估计
本节分析迭代法的收敛性和迭代过程的误差
迭代法收敛性
预测序列是否收敛 ? 收敛定理(充分条件)
收敛定理保证了每迭代一次,
\(x\)
离精确解
\(x^*\)
都更近

自映射是为了证明根的存在性、导数绝对值小于1是为了证明根的唯一性和收敛性
另外,魏尔斯特拉斯定理说明闭区间上的连续函数一定在该区间上取得最大值和最小值,故只要
\(|φ'(x)|<1\)
,就一定存在
\(|φ'(x)| \le L < 1\)

使用微分第一中值定理证明

使用微分第一中值定理证明

当不满足迭代定理时,可能需要改变迭代方程或者初值所在区间
\([a,b]\)
,如何判断是迭代函数取得不好,还是区间
\([a,b]\)
取得过大?
引入局部收敛性的概念

可以发现,如果满足局部收敛性,只要
\([a,b]\)
区间取得够好,一定收敛,也就能确定不是迭代函数取得不好,而是区间
\([a,b]\)
取得过大

定理很好证明,首先局部收敛性只需要证明收敛皆可,解的存在和唯一是显然成立的。又
\(φ'(x)\)
是连续的,
\(|φ'(x^*)| < 1\)
可以推出存在一邻域使得邻域内的点都满足
\(|φ'(x)| \le L < 1\)
,则
\(|φ(x) – x^*| = |φ(x) – φ(x^*)| \le L(x – x^*)\)
,也就说明迭代一次之后新的 $x $ 更接近精确解了,故序列是收敛的
该定理可以简单地判断出迭代方程是否具有局部收敛性,但要求提前知道准确解,这显然是不可能的
故采用如下不太严格的准则来判断迭代方程选得好不好

迭代过程误差估计
在满足收敛定理的前提下,误差的分析很简单

证明

意义

迭代法的收敛速度及加速处理



加速过程:


类似于预报-校正,又有点像理查德森外推的过程

从这个式子中求解出
\(x^*\)
或者直接参照结论

牛顿法
牛顿法是一种通用的构造迭代方程的方法,构造出来的迭代方程满足局部收敛且收敛速度为平方收敛(即
\(φ'(x^*) = 0\)
)
做法是:对于求解
\(f(x) = 0\)
的问题,对
\(f(x)\)
在近似解
\(x_0\)
处进行泰勒展开且展开到二阶,则
\(f(x) ≈ f(x_0) + f'(x_0)(x – x_0) = 0\)
, 这样得到一个线性方程可以直接求解,若
\(f'(x_0) \ne 0\)
,则有新的解
\(x_1 = x_0 – \frac{f(x_0)}{f'(x_0)}\)
,我们接下来在
\(x_1\)
处进行泰勒展开,并重复这一过程。那么我们的迭代公式就是
\(x_{n+1} = x_n – \frac{f(x_n)}{f'(x_n)}\)
,其中
\(f'(x) \ne 0\)
这样构造出来的迭代公式满足下面的性质:


注意性质应满足的条件:单根+
\(f(x)\)
有连续二阶导数
证明:


几何意义

计算步骤

注意迭代终止的条件是
\(|x_{n+1} – x_n| < \epsilon\)
牛顿法初值的选取
牛顿法是一种局部收敛的算法,如果初值
\(x_0\)
选择的不恰当,就有可能得不到收敛的迭代序列
为使牛顿法收敛,必须满足:用迭代公式算出的
\(x_1\)
比
\(x_0\)
更靠近准确根
\(x^*\)
根据牛顿法的几何意义可以发现
\(f'(x)\)
为0或者很小,都不能很快收敛



条件二是为了让条件一有意义
牛顿法的soft版本

the end ……









